¿Qué es CNN en Deep Learning? La IA detrás de la Visión por Computador
¿Alguna vez te has preguntado cómo Google Fotos reconoce tu rostro y agrupa tus fotos? Eso es CNN (Red Neuronal Convolucional) en acción, que clasifica imágenes basándose en características similares. CNN es un tipo de red neuronal en el campo de la IA que permite a los sistemas informáticos procesar información visual con gran precisión. Así que para aprender más sobre CNN en Deep Learning, sigue nuestra explicación a continuación.
¿Qué es CNN en Deep Learning?
CNN o Red Neuronal Convolucional es un tipo especial de red neuronal en deep learning diseñada para procesar datos con estructura de cuadrícula, particularmente imágenes. Si bien existen diferentes tipos de redes neuronales que pueden analizar imágenes, tienen dificultades para reconocer patrones en ellas porque tratan cada píxel como una característica independiente. Básicamente, se vuelve computacionalmente abrumador para el sistema analizar cada píxel.
Las CNN, por otro lado, pueden reconocer patrones en datos visuales de manera mucho más eficiente. CNN en deep learning funciona de manera similar a cómo los humanos procesamos imágenes o cualquier información visual. No analizamos cada píxel individual; en cambio, nuestro cerebro identifica bordes, formas, texturas y gradualmente reconoce objetos completos como rostros, coches o animales.
Básicamente, CNN en deep learning se refiere a este tipo de red neuronal que sigue un enfoque jerárquico para identificar información visual.
¿Cómo funcionan realmente las CNN?
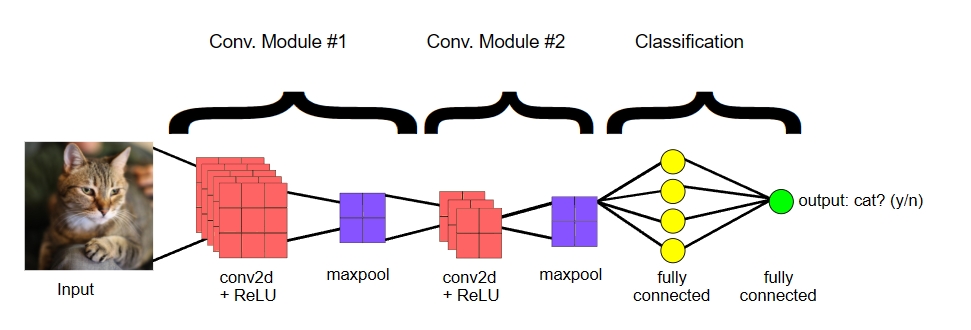
Las Redes Neuronales Convolucionales (CNN) tienen una arquitectura en capas donde cada capa extrae características complejas de una imagen. En primer lugar, la capa Convolucional, que es la más importante, utiliza pequeños filtros que se deslizan a través de la imagen. Busca patrones específicos en la imagen. Puede detectar detalles básicos como líneas horizontales, verticales o bordes.
A medida que la red se profundiza, los filtros comienzan a reconocer patrones complejos como curvas y texturas. Gradualmente, la red reconoce el objeto completo. Para darte un ejemplo, cuando sostienes una pequeña lupa y la mueves a través de una pintura, miras alrededor para examinarla. De manera similar, la capa Convolucional se desliza a través de la imagen y realiza operaciones matemáticas para encontrar si ciertas características están presentes o no.
Ahora, las capas de pooling (agrupación) toman estas características extraídas y reducen las dimensiones espaciales de los datos. Simplemente significa que solo mantiene la señal más fuerte de cada región para que la red pueda procesar los datos de manera eficiente. Luego, las capas totalmente conectadas en las CNN toman estas características extraídas para clasificar la imagen.
Si la CNN está entrenada para reconocer animales, obtienes "esta imagen contiene un perro" basándose en todas las características extraídas de las capas anteriores. Así es como funciona la IA para reconocer objetos en imágenes turismocalasparra.es.
También te puede interesar: ¿Quién creó la IA? Rastreando la Historia de la Inteligencia ArtificialLa historia del origen de la CNN
El desarrollo detrás de la CNN es bastante interesante. Yann LeCun es ampliamente reconocido como el creador de las CNN modernas, quien introdujo una red que podía reconocer dígitos escritos a mano en 1989. Sin embargo, mucho antes, en 1980, el informático japonés Kunihiko Fukushima introdujo el "Neocognitrón", que sentó las bases de cómo las redes en capas podían procesar información visual.

El Neocognitrón de Fukushima estaba ciertamente muy adelantado a su tiempo e introdujo muchos conceptos clave, como la detección jerárquica de características utilizada en las CNN. Sin embargo, LeCun añadió la retropropagación para entrenar las CNN, lo que permitió a la red aprender automáticamente de los datos. En cierto modo, LeCun popularizó el uso de la CNN.
Un desarrollo importante ocurrió en 2012 cuando Alex Krizhevsky, Ilya Sutskever y Geoffrey Hinton introdujeron una CNN llamada AlexNet que ganó la competencia ImageNet por un margen significativo, derrotando a todos los otros enfoques tradicionales. Esto demostró que con suficientes datos y poder de cómputo, las CNN pueden superar a los métodos tradicionales para el análisis de visión.
¿Cómo se entrenan las CNN?
Para entrenar una CNN, necesitas una enorme cantidad de datos etiquetados. Básicamente, para clasificar imágenes, necesitas millones de imágenes etiquetadas con la descripción de la imagen. La red ahora hace predicciones, las compara con las respuestas correctas y ajusta sus parámetros para mejorar la precisión y el rendimiento. Este proceso se llama retropropagación y se repite millones de veces hasta que la red aprende a reconocer patrones de las imágenes.
El futuro de las CNN
Aunque la CNN ha tenido un impacto enorme en el campo de la Inteligencia Artificial (IA), nuevas tecnologías como los Vision Transformers (ViT) están mostrando un mejor rendimiento y precisión. Estos son básicamente modelos basados en Transformers, que utilizan secuencias de parches para procesar imágenes en lugar de usar filtros convolucionales. Claro, los ViT son más precisos y potentes, pero también necesitan más recursos computacionales.
En ese sentido, las CNN son más eficientes y pueden usarse en dispositivos de borde como teléfonos móviles donde tienes recursos computacionales limitados. En cualquier caso, la CNN ha avanzado significativamente el campo del deep learning, ya que finalmente permitió a los sistemas informáticos procesar y comprender información visual.
Contenido original en https://beebom.com/cnn-in-deep-learning/
Si cree que algún contenido infringe derechos de autor o propiedad intelectual, contacte en [email protected].
Copyright notice
If you believe any content infringes copyright or intellectual property rights, please contact [email protected].