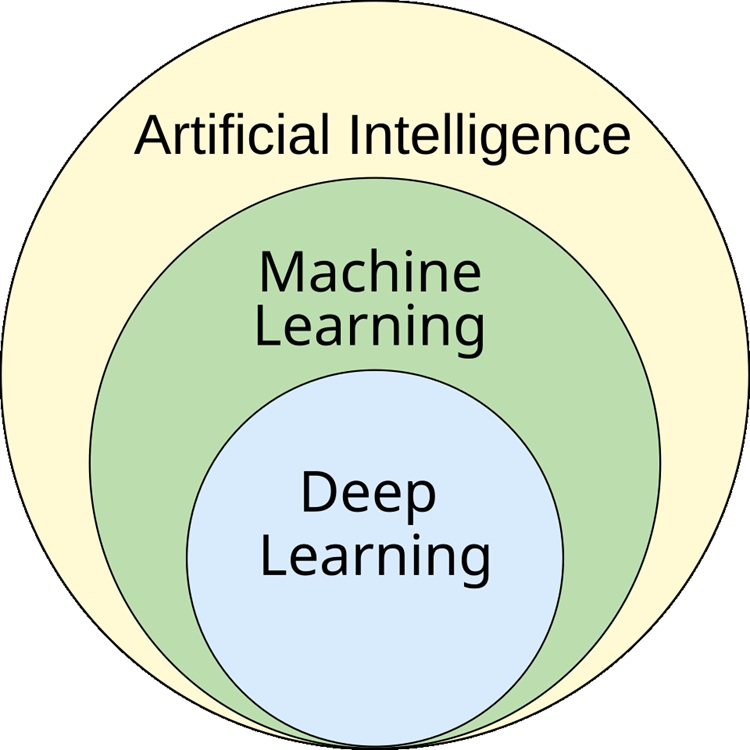
¿Cuál es la Diferencia Entre Aprendizaje Profundo y Aprendizaje Automático?
En el campo de la inteligencia artificial, tanto el aprendizaje automático (ML) como el aprendizaje profundo (DL) juegan un papel importante en cómo la IA aprende de los datos en bruto. Sin embargo, operan de maneras diferentes, y aún así mucha gente los confunde. Así que permíteme ayudarte a aclarar tus dudas y explicar la diferencia entre aprendizaje profundo y aprendizaje automático en esta lectura.
¿Qué es el Aprendizaje Automático?
Los modelos o algoritmos de aprendizaje automático pueden aprender de los datos y hacer predicciones por sí mismos. No necesitan que los humanos programen explícitamente cada regla sobre cómo aprender y producir un resultado. De ahí la parte de "aprendizaje". Sin embargo, en el aprendizaje automático tradicional, los humanos sí necesitan etiquetar manualmente cada característica de los datos.
Por ejemplo, si quieres que sepa cómo es un gato, necesitas indicar sus características distintivas, como orejas, bigotes, cola y patas. Por eso el aprendizaje automático tradicional es más adecuado para conjuntos de datos estructurados a pequeña escala.
Lee también: IA vs Aprendizaje Automático: ¿Cuál es la Diferencia?Tipos de Modelos de Aprendizaje Automático
El campo del aprendizaje automático es bastante amplio y engloba al aprendizaje profundo como un subconjunto, pero existen principalmente tres tipos principales.
- Aprendizaje Supervisado: Este modelo de aprendizaje automático utiliza datos etiquetados donde las características y el objetivo están claramente definidos. Esto ayuda a minimizar los errores de predicción y se utiliza típicamente para identificar correos no deseados o predecir precios de viviendas.
- Aprendizaje No Supervisado: A los algoritmos de aprendizaje no supervisado se les dan datos sin etiquetar, como una imagen, y aprenden patrones y relaciones de forma independiente. Lo hacen formando agrupaciones y utilizando múltiples capas ocultas de redes neuronales.
- Aprendizaje por Refuerzo: Este modelo aprende de su entorno basándose en un método de prueba y error. Hará predicciones aleatorias hasta que acierte una, y será recompensado por ello. Por otro lado, también puede ser penalizado por hacer una suposición incorrecta. Este algoritmo se ve comúnmente en robots y coches autónomos.
Casos de Uso de los Modelos de Aprendizaje Automático
El aprendizaje automático en la Inteligencia Artificial se ha vuelto bastante común últimamente, y la demanda ha aumentado en muchos campos. Aquí hay algunas aplicaciones cotidianas de estos modelos:
- Detección de correo no deseado y clasificación de correos electrónicos
- Motor de recomendación y anuncios personalizados
- Detección de fraude y marcado de actividades sospechosas
- Clasificación en motores de búsqueda, como la que utiliza Google
- Predicción del precio de la vivienda
¿Qué es el Aprendizaje Profundo?
El aprendizaje profundo es un subconjunto del aprendizaje automático, como he explicado anteriormente. A diferencia del aprendizaje automático tradicional, el aprendizaje profundo puede aprender automáticamente características de los datos en bruto sin necesidad de ingeniería manual de características. Los datos pueden estar etiquetados o no, dependiendo de la tarea spain-incoming.es.
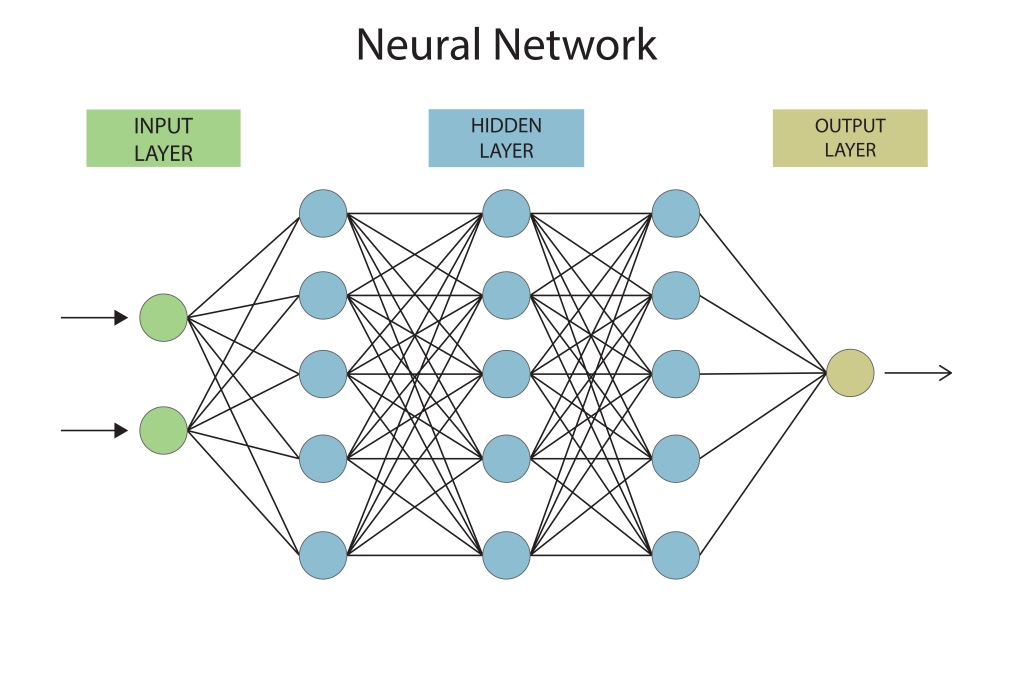
Lo hace utilizando múltiples capas ocultas de redes neuronales que extraen y aprenden automáticamente patrones cada vez más complejos. El aprendizaje profundo se utiliza ampliamente hoy en día en chatbots de IA, generadores de imágenes, creación de vídeo y música, modelos de lenguaje grandes, así como en traducción de idiomas.
Tipos de Modelos de Aprendizaje Profundo
Al igual que el aprendizaje automático, los modelos de aprendizaje profundo también tienen una variedad de arquitecturas basadas en diferentes casos de uso. Aquí tienes un desglose de ellas.
- Redes Neuronales Convolucionales (CNN): Utilizan filtros convolucionales para extraer automáticamente características de datos visuales, detectando patrones como bordes, texturas y objetos. Son las más adecuadas para imágenes y vídeos.
- Redes Neuronales Recurrentes (RNN): Procesan datos secuenciales manteniendo información de pasos anteriores. Permite a la red entender el contexto y el orden. Se utilizan principalmente en reconocimiento de voz y asistentes digitales.
- Redes de Memoria a Largo Plazo (LSTM): Es un tipo de RNN que aborda el problema del gradiente que se desvanece, permitiendo a la red retener información en secuencias más largas. Se utilizan para cosas complejas como modelos de lenguaje.
- Redes Generativas Antagónicas (GAN): Están compuestas por una red neuronal Generadora y otra Discriminadora, donde una crea nuevos datos para intentar engañar a la otra. Se utiliza para crear imágenes, vídeos, texto y música de IA.
- Arquitectura Transformer: Este es el pilar de los actuales modelos de lenguaje grandes como ChatGPT, Google Gemini y Microsoft Copilot. Cuenta con un componente llamado Autoatención que prioriza ciertas partes de los datos sobre otras.
Casos de Uso de los Modelos de Aprendizaje Profundo
El aprendizaje profundo es una rama del aprendizaje automático, pero su uso ha evolucionado mucho y se está adoptando ampliamente en diversas industrias. Aquí hay algunos ejemplos.
- Reconocimiento de imágenes y objetos
- Modelos de lenguaje grandes como ChatGPT, Gemini y Copilot
- Generación de imágenes, vídeo y música
- Creación de algoritmos personalizados para redes sociales en aplicaciones como TikTok, YouTube e Instagram
- Conversión de lenguaje hablado en texto
Aprendizaje Profundo vs Aprendizaje Automático: Diferencias Clave
Ahora que hemos examinado bien ambos modelos, es hora de que finalmente comparemos los dos y descubramos las diferencias entre aprendizaje automático y aprendizaje profundo.
| Característica | Aprendizaje Automático (ML) | Aprendizaje Profundo (DL) |
| Tamaño de Datos | Funciona bien con conjuntos de datos pequeños a medianos. | Requiere cantidades masivas de datos para alcanzar el máximo rendimiento. |
| Hardware | Puede ejecutarse en CPUs estándar. | Requiere GPUs o TPUs de gama alta para el entrenamiento. |
| Extracción de Características | Requiere ingeniería manual de características. | Las características son aprendidas directamente por la red. |
| Arquitectura | Utiliza algoritmos tradicionales (árboles de decisión, SVM, etc.) o redes neuronales poco profundas | Utiliza Redes Neuronales Profundas (3+ capas ocultas). |
| Rendimiento | El rendimiento a menudo se estanca a medida que aumenta el volumen de datos. | El rendimiento continúa aumentando con el aumento del volumen de datos. |
| Interpretabilidad | Es más fácil entender cómo el modelo llegó a su decisión (menos de una "caja negra"). | Es más difícil interpretar el proceso de toma de decisiones ("caja negra"). |
Contenido original en https://beebom.com/deep-learning-vs-machine-learning/
Si cree que algún contenido infringe derechos de autor o propiedad intelectual, contacte en [email protected].
Copyright notice
If you believe any content infringes copyright or intellectual property rights, please contact [email protected].